
DynamoDB is one of the most widely used services that AWS offers. We wrote another blog post recently about some adjustments you can make to your existing Dynamo Table that can reduce cost without causing any unintended side-effects.
In this blog post longer blog post we want to highlight a few things that are important to keep in mind the next time you design a Dynamo table schema. Getting this right from the beginning can save you a lot of money, and time than wanting to course correct it at a later point.
Unlike the previous post about Dynamo, most of the things we talked about are now contextual, meaning you can’t follow them blindly but rather you need to decide according to the context and the scale you are operating.
Table per entity vs Flat table
Most developers who are comfortable with SQL gravitate towards having a separate table per entity and that is not necessarily wrong but very soon they come across a use-case that they need to do a “JOIN” and then realized that Dynamo doesn’t support a “JOIN” statement. The most common approach to overcome this is to perform “JOIN” at the application layer.
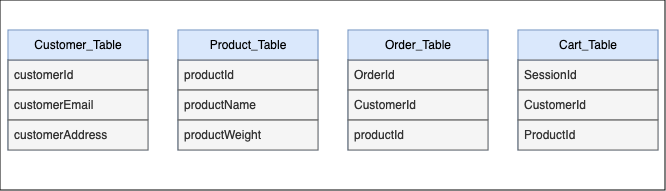
Doing “JOIN” at the application level has two drawbacks, first one is that it add extra latency as you have to make sequential calls to Dynamo and Query two (or even more) tables and map the values at your app layer before sending it downstream services, the other drawback is related to cost efficiency. This approach can increase the RCU as you now have to query multiple tables to get the result that you require. REMEMBER DynamoDB is optimized for scenarios where you can access data with a single, predictable query pattern, meaning the more you can avoid using filtering, the better it is.
PK | SK | OrderID | ProductID | ProductName | CustomerID | OtherAttributes
-------------------------------------------------------------------------------------------
Customer#123 | 2023-10-05 | ORDER#23 | Product#A | Shoes | Customer#1 | X
Customer#123 | 2023-10-06 | ORDER#24 | Product#B | Watch | Customer#1 | Y
Customer#2 | 2023-10-07 | ORDER#12 | Product#A | Shoes | Customer#2 | Z
Above is an illustration of flattening the Order History table for our e-commerce scenario. Using this approach the order history page can be displayed by making a single call to a single DynamoDB table without any filtering.
You might be wondering Why is Sort Key set on OrderDate and not OrderID. REMEBER earlier, the goal is to avoid filtering for as much as possible. by setting the SORT KEY on order date, we can fetch orders for a giving customer within a specific date range without the use of filtering, but of if we were to set SortKey on Order ID, we’d have to fetch ALL the orders for any given customer first and then only filter out the ones needed based on specific date range.
# DESIRED: Query to get orders within a specific date range WITHOUT using Filtering
response = table.query(
KeyConditionExpression=Key('CustomerID').eq(customer_id) & Key('OrderDate')
.between('2023-10-05', '2024-10-07')
)
# NOT DESIRED: Query to get same orders when ORDER DATE isn't set as SORT KEY.
response = table.query(
KeyConditionExpression=Key('CustomerID').eq('Customer#1'),
FilterExpression=Attr('OrderDate').between('2023-10-05', '2024-10-07')
)
A word of caution before going all in with flatten table approach:
We talked about how contextual this topic is, and while one approach can be considerably more performant than the other but it is not guaranteed in all use-cases nor taking the approach to extreme can increase its effectiveness.
The same is true for flattening Dynamo Table. a side-effect of flattening table is that it leads to higher item size on average which has two drawbacks:
- it could lead to Dynamo max item size of 400 KB.
- Having too many properties that often need to be updated independent of other attributes can lead to higher “RCU”, and “WCU” costs. This is because in order to update one attribute, you need to read the entire item, make the update for the particular attribute on that item, and then write the entire item back to dynamo.
Our guideline after working with several customers on this topic is to think about what business functionality is this table serving. Going back to the e-commerce example, if you are loading a page that displays order history of a given customer it most likely spans over several domains such as “customer”, “products”, and “orders”. This is a clear example of benefiting from both performance and cost if you have a flatten table structure that can retrieve all the attributes from a single table.
On the contrary, if you have one attribute in your domain that gets updated way more frequently than any other attributes, a flatten table shall be avoided. An example of this scenario would be a counter that counts the number of people who have watched a video on a social media site. the watch counter is most likely going to be updated more frequently than any other attributes such as title, and etc. in a flatten table structure you can’t update the number without reading and writing back the entire attributes thus leading to higher “RCU” and “WCU”.
Vertical Partitioning:
In short, Vertical Partitioning (VP) can be a game Changer! 😀
VP is a great approach to overcome the negative side-effects of flattening table which were primarily reaching the limit of 400kb items size as well as unwanted increase in “RCU”, and “WCU” cost.
in nutshell, Vertical Partitioning is the practice of breaking down large number of rows with several attributes into smaller chunk BUT store them all in the SAME table AND be able to rely on primary key (PK) and sort key (SK) for retrieving the particular chunk that you are interested at any given time.
Okay, that was quite a mouthful statement, let’s see it in action:
To show a small proof of concept, below is a dynamo Table for the e-commerce example we talked about earlier that has a primary key called “PK” and a sort key called “SK”. We then have written the following item into Dynamo:
Item: {
'pk': 'customer#123', // customerId is the primary key
'sk': 'PROFILE#BASE', //the sort key determines what chunk of customer info are being recorded in this row.
'name': 'John Doe',
'email': '[email protected]',
'phone': '+15845495747'
}
The next item in the same table look something like this:
Item: {
'pk': 'customer#123', // customerId is the primary key
'sk': 'PROFILE#ADDRESS', // the sort key determines what chunk of customer info is being recorded in this row.
'Address1': 'John Doe st',
'City': 'New York',
'PostCode': '2343223'
}
And the third item on the same table is:
{
'pk': 'customer#123',
'sk': 'ORDER#54384', // this indicates this row has order info of the respective customer
'OrderDate': '2024-10-10',
'OrderStatus': 'Completed',
'OrderItems': [
{'productId': '324232', 'Quantity': 2},
{'productId': '342342', 'Quantity': 1}
]
}
Based on this design you will end-up with table that looks something like this:

We now have managed to store customer info, and their order history, in the same table by breaking it into distinguishable chunks that can be queried using PK (customerID) and Sort key. If we now want to retrieve customer email and phone number, we can do so without having to fetch any other attributes using “PROFILE#BASE” as the sort key.